
Dimensional data models have been around for a very long time, almost certainly tracing their lineage back to the original Data Cube project between Dartmouth and General Mills in the late 1960s. The appeal of dimensional modeling stems from the obvious simplicity of the models and the natural way in which both business people and technical folks can understand what the models mean.
Dimensional models have two distinctly different expressions, logical and physical. The purely logical expression is the bubble diagram.
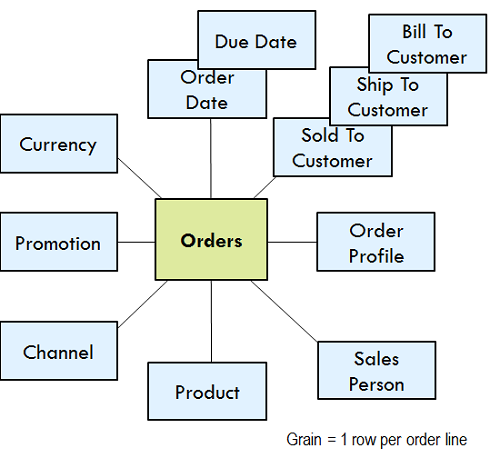
The box in the center always represents event measurements, e.g., order line items in the example. We call these facts. The bubbles around the edge represent the natural dimensions associated with the event measurements. There is very little database technical content in the bubble diagram logical model, but a lot of business content. Once the source of the fact measurements has been identified, the logical model is the place to begin the serious design.
Once agreed to, the bubble diagram logical model morphs fairly rapidly into a much more specific technical design replete with table names, field names, and primary key-foreign key declarations. This is what most IT folks think of as a dimensional model. Hmmm, this looks pretty physical. When this physical design has been declared, it seems like the only remaining step is to write the explicit DDL creating all the target tables, and then get down to the business of implementing the ETL pipelines to populate these physical tables.
Wait. Not so fast! If we are honest about this very physical appearing dimensional model, we have to admit that at the true physical storage level, our dimensional model may be implemented very differently. The two big elephants in the room are columnar databases and data virtualization. Columnar databases radically rearrange the data into sorted and compressed columns while preserving the surface illusion of the original dimensional model. Data virtualization transforms actual physical data in almost any original form at query time while preserving the surface illusion of the original dimensional model. Extreme forms of data virtualization popular in the Hadoop world are sometimes called “deferred binding” or “schema on read.” But in all cases, the end result is the familiar dimensional model.
Rather than getting hung up on religious arguments about logical versus physical models, we should simply recognize that a dimensional model is actually a data warehouse applications programming interface (API). The power of this API lies in the consistent and uniform interface seen by all observers, both users and BI applications. We see that it doesn’t matter where the bits are stored or how they are delivered when an API request is launched.
The dimensional model API is very specific. It must expose fact tables, denormalized dimension tables, and single column surrogate keys. The requesting BI application cannot and must not care how the results sets are actually implemented and delivered. We see now that the true identity of the dimensional model is as a data warehouse API.
